《空间理论评估框架发布:当AI的认知地图遭遇三岁孩童困境
1981年的一个午后,发展心理学家SimonBaron-Cohen设计了一个改变认知科学进程的实验。三十年后,这个实验的变体成为衡量人工智能空间智能的重要标尺。
从Sally-Anne测试到空间智能评估
经典Sally-Anne测试揭示了人类认知发展的关键节点:四岁孩子能理解"自己知道"与"他人知道"的差异,三岁以下则无法区分。这种"心智理论"能力,被认为是人类社会化的认知基础。
斯坦福大学李飞飞团队与西北大学李曼玲团队的联合研究,将这个测试框架迁移到AI领域。他们设计的"空间理论"(TheoryofSpace)评估框架,首次系统性地考察了大语言模型在物理空间中的主动探索与信息整合能力。
被动答题与主动探索的鸿沟
传统空间智能评估采用"开卷考试"模式:给定完整场景信息,要求模型输出位置关系。这种测试下,主流大模型表现优异,准确率普遍超过85%。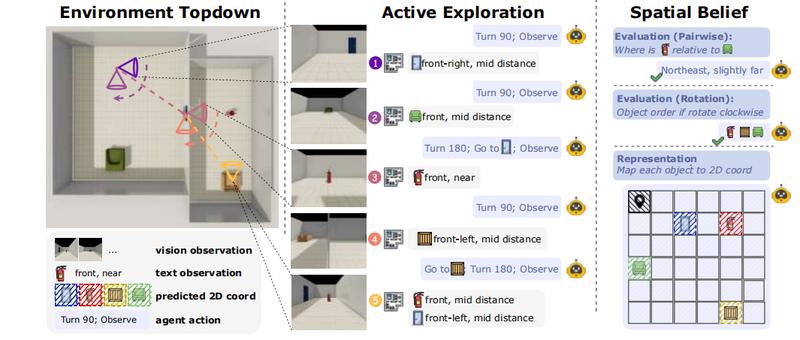
但现实世界从不是开卷考试。研究团队的测试环境模拟了多房间物理空间,模型必须主动移动、探索、收集碎片化信息,逐步构建完整的认知地图。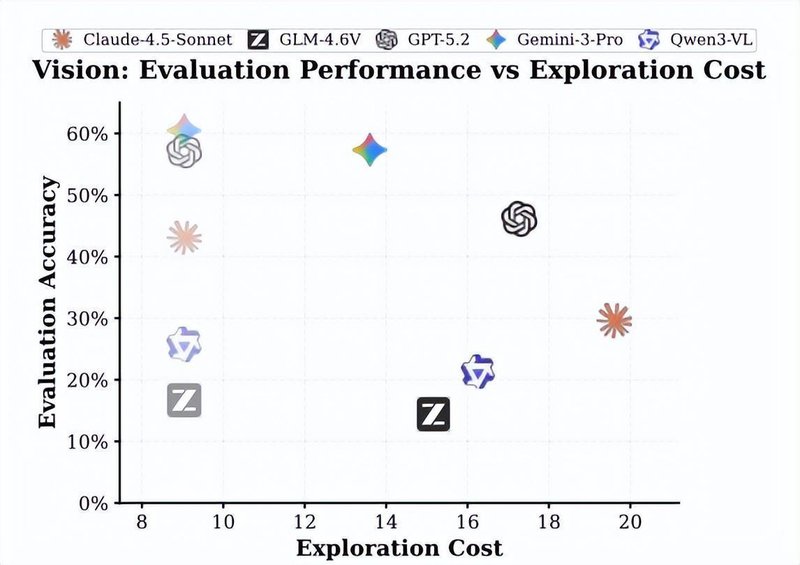
结果显示,从被动模式切换到主动探索模式后,GPT-5.2准确率从57.1%骤降至46.0%,下降11.1个百分点。Gemini-3Pro从60.5%降至57.3%。这个"主动-被动差距"揭示了当前AI系统的核心缺陷:它们擅长处理已给出的信息,却难以自主获取和整合空间知识。
信念惯性:AI的认知锁定现象
研究团队设计了"错误信念测试"来诊断模型的认知过程。在模型完成初次探索后,系统悄悄移动或旋转部分物体。当模型再次观察到新布局时,一个令人警觉的现象出现:GPT-5.2在视觉模式下的"朝向惯性"高达68.9%,意味着近七成情况下模型仍坚持报告物体的旧朝向。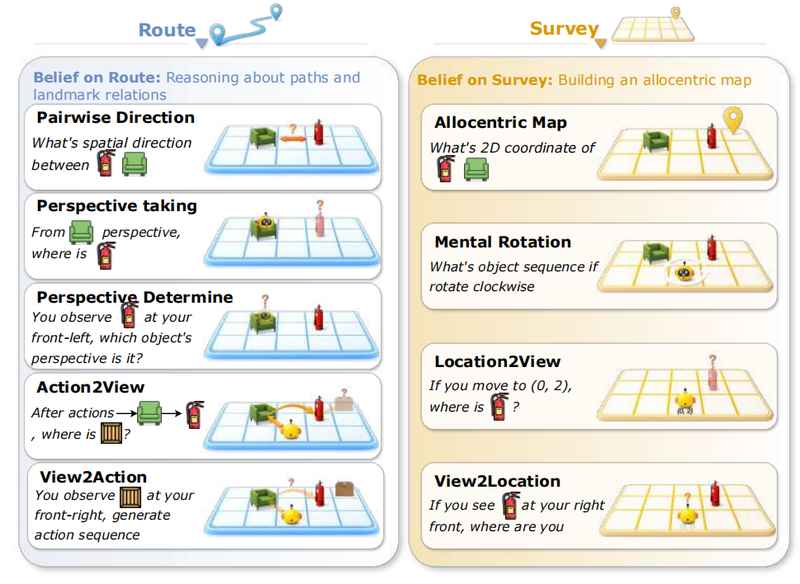
同一模型在文本模式下的惯性仅为5.5%。这个巨大差异指向一个根本问题:模型能够更新文本表征,却难以覆写视觉空间表征。模型亲眼目睹了变化,但内部认知地图拒绝更新——这正是Sally-Anne测试中三岁幼儿的典型失败模式。
认知漂移:记忆的侵蚀与覆盖
研究发现,在连续探索过程中,模型早期建立的正确空间记忆会逐渐被后续错误更新覆盖。首次观察物体的感知误差本不严重,但随着探索步骤增加,这些误差不断累积,最终导致整体认知地图失真。
文本世界与视觉世界的表现差异同样显著。人类被试在视觉世界的准确率达96.4%,文本世界为86.7%。模型却呈现相反模式——文本表现远优于视觉。视觉信息对人类是直觉通道,对当前多模态模型却是更高难度的挑战。
物体朝向识别:几乎等同于随机猜测
模型在视角推理任务上的准确率仅约36%,几乎等于随机猜测。这解释了为何多模态大模型在需要空间推理的任务中表现挣扎。它们能从像素中识别物体,却无法准确理解物体在空间中的朝向与方位关系。
框架价值:从二元判定到分级诊断
空间理论评估框架的核心贡献在于将空间智能从"会/不会"的二元判断,转变为可逐级诊断的连续评估体系。它不仅告诉开发者模型距离目标有多远,更精确定位了模型在哪个认知层级开始失效。
对于需要主动导航的真实应用场景——如灾区搜救、工厂巡检、家庭机器人——当前的AI系统仍有很长的路要走。如果连"记住刚才看到的沙发位置"都无法可靠完成,遑论复杂环境中的主动探索与决策。



